
The OSINT Newsletter - Issue #15
Building your own local OSINT database

Open source intelligence is extremely powerful because it puts collection, exploitation, and analysis in the hands of anyone who is interested. With the power of a search engine, a few free tools, and an appetite to learn, anyone can go from zero to OSINT hero in a short period of time with enough dedication. But OSINT sometimes has its limitations. There’s a saying that the internet is forever but as any long term OSINT practitioner knows, that’s not always true. Sometimes you have to hedge your bets and keep things local.
In this issue of The OSINT Newsletter we’re going to discover how you can not only secure open source intelligence forever but how you can increase your value as an OSINT practitioner in the process; because if anyone can do OSINT, how are you, objectively, any more valuable than someone else?
This issue will as usual combine a little bit of technical and nontechnical OSINT tools, tactics, and techniques; in particular, we’re going to look at capabilities everyone has on the devices they use every day.
OSINT Tools
Simplescraper - simplescraper.io
Since this issue’s theme is creating a local OSINT database that you can reference without relying on the internet’s permanence, we of course must start with web scraping. Now, I will say that learning web scraping using Python is one of the easiest ways to get started with the language; however, if you’re anything like me you know you’re not a developer and never will be. With that in mind, I present Simplescraper.
Unlike other free scraping tools, Simplescraper can be completely customized to suit your needs without relying on table identification and other methods. It’s also incredibly easy to set up. Find your target element using developer tools, copy, paste, label, and scrape.
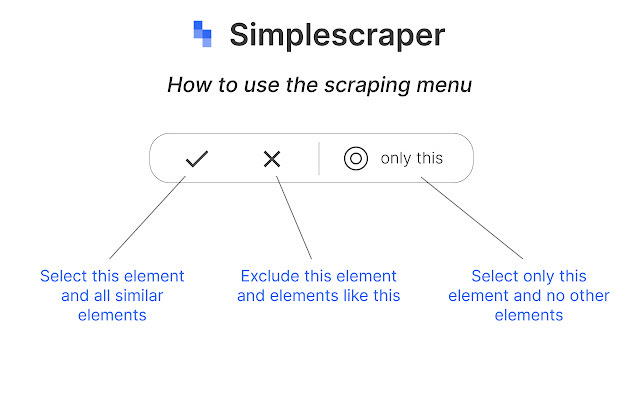
Now, why would you need to use Simplescraper? Certain types of data online are ephemeral, or temporary. Think Telegram channels, Twitter followers, Instagram comments, etc. Because those data points can disappear at any moment, it’s important to capture them if they are important to your investigation and store them properly.
Simplescraper allows you to capture information from a variety of websites to do just this; furthermore, it allows you to create ‘recipes’ so repetitive tasks don’t become mundane. Set up a recipe for a Telegram channel and reuse it over and over as you pivot across networks.
Alternative: Instant Data Scraper
Image Downloader - Chrome Extension
Images can be harder to scrape. If you use a tool like Simplescraper for images, you’ll probably only get the link to the image. I ran into this issue using Instant Data Scraper in the past resulting in me writing ImageSwipe to download images from image URLs. Fortunately there are several Chrome extension that allow you to download all images present on a page for later review.
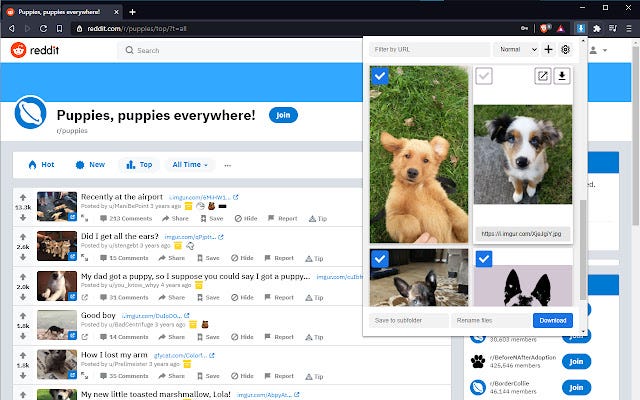
Why would you want to download images? As you’ll see in the OSINT Techniques section later, there are a variety of tools you can use to search images using OCR or facial recognition. That said, much like comments, links, and text-based content, photos can disappear at a moments notice. Image hosting services like Imgur can take content down or delete accounts. A key piece of evidence in your investigation can be lost at any time.
Save early and often, including images.
Alternative: Imageye
ModernCSV - moderncsv.com
If you scrape enough data, you’ll soon realize that common tools like Excel and Google Sheets have trouble loading large datasets. Sometimes it crashes the tool completely or takes minutes to load. Here’s where ModernCSV comes in. Not only is it designed with engineers in mind, it has all sorts of handy tools for OSINT investigators.

Editing with ModernCSV is amazing. It gives you the ability to move groups of cells around together without interfering with the existing structure of your spreadsheet. Finding data within your spreadsheet is much easier with ModernCSV as there are far more custom options. Finally, it can open huge CSV files. I’ve opened 1gb+ CSV files in just a few seconds using the tool.
I used to use Tablecruncher for this job until I discovered ModernCSV. The only reason ModernCSV is recommended instead of Tablecruncher is because Tablecruncher now has an expired SSL cert and costs $29.99 whereas ModernCSV is free with a premium option for more functionality.
Alternative: Tablecruncher (expired SSL!) :(
Imgrep - Github
Using a browser extension or other tools for downloading images can create a rather large database of images in a short period of time. The issue with a large set of images is that it’s difficult to reference them later without sifting through them one by one. There are a few ways to process images in bulk. Among them are optical character recognition (OCR), facial recognition, and hashing the images and using a variety of algorithms to calculate similarity among images.
Imgrep is a command line and web UI tool that allows you to use an open source library for OCR to search for keywords within your image dataset the same way you search for keywords in your text-based data with grep.

Now, the configuration of imgrep can be pretty intimidating for a non-technical OSINT practitioner. First, it’s written in Go which is similar to Python but not identical. Second, it requires you to install Tesseract, the open source library for OCR. Finally, it requires you to set a path for $GOPATH which in its nature is similar to configuring Geckodriver or Chromedriver for selenium and web scraping.
The wiki of the Github page goes through this process in detail, making it easier to set up, and once you have it set up you’ll find yourself using it often and encouraging you to grow your own image database.
Remember #OSINT != tools. Tools help you plan and collect data but the end result of that tool is not OSINT. You have to analyze, verify, receive feedback, refine, and produce a final, actionable product of value before it can be called intelligence.
This is the end of the free subscription to The OSINT Newsletter. To see practical applications of OSINT tactics and techniques, please consider supporting this publication with a paid subscription.
Paid subscribers get access to practical OSINT tactics and techniques I haven’t published publicly online. This issue will look at practically applying tactics and techniques for creating your own OSINT archive and searching within it for insights when popular search engines fail.
